Interval zaupanja
Kaj je interval zaupanja:
Gre za oceno obsega, ki se uporablja v statistiki, ki vsebuje parameter prebivalstva. Ta neznani populacijski parameter se najde v vzorčnem modelu, izračunanem iz zbranih podatkov .
Primer: povprečje zbranega vzorca x̅ lahko ali ne ustreza pravemu povprečju populacije μ. Pri tem je mogoče upoštevati vrsto vzorčnih sredstev, kjer je ta populacijska sredina lahko zadržana. Daljši kot je ta interval, večja je verjetnost, da se to zgodi.
Interval zaupanja je izražen kot odstotek, izražen s stopnjo zaupanja, pri čemer je 90%, 95% in 99% najbolj označeno. Na spodnji sliki imamo na primer 90% interval zaupanja med njegovo zgornjo in spodnjo mejo (a in -a ).
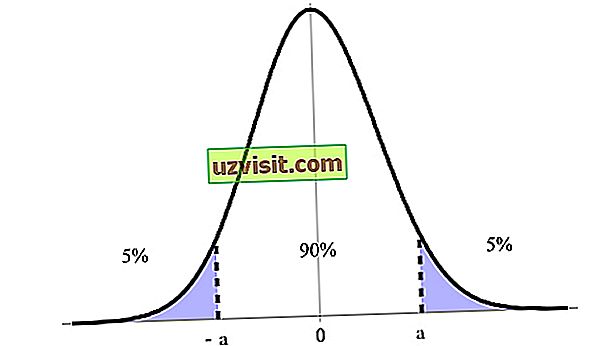
Interval zaupanja je eden izmed najpomembnejših konceptov v testiranju hipotez v statistiki, saj se uporablja kot merilo negotovosti. Izraz je predstavil poljski matematik in statistik Jerzy Neyman leta 1937.
Kakšen je pomen intervala zaupanja?
Interval zaupanja je pomemben za označevanje stopnje negotovosti (ali nenatančnosti) glede na izračun. Ta izračun uporablja študijski vzorec za oceno dejanske velikosti rezultata v izvorni populaciji.
Izračun intervala zaupanja je strategija, ki upošteva vzorčenje napak. Velikost rezultatov vaše študije in vaš interval zaupanja označujeta domnevne vrednosti za prvotno populacijo.
V ožjem intervalu zaupanja, večja je verjetnost, da odstotek študijske populacije predstavlja realno število izvorne populacije, kar daje večjo gotovost glede na rezultat študijskega predmeta.
Kako interpretirati interval zaupanja?
Pravilna razlaga intervala zaupanja je verjetno najzahtevnejši vidik tega statističnega koncepta. Primer najpogostejše interpretacije koncepta je naslednji:
Obstaja 95-odstotna verjetnost, da bo v prihodnosti prava vrednost populacijskega parametra (npr. Povprečje) padla v območju X (spodnja meja) in Y (zgornja meja).
Tako je interval zaupanja interpretiran na naslednji način: 95% je prepričan, da interval med X (spodnja meja) in Y (zgornja meja) vsebuje pravo vrednost populacijskega parametra.
Popolnoma napačno bi bilo trditi, da: obstaja 95-odstotna verjetnost, da interval med X (spodnja meja) in Y (zgornja meja) vsebuje realno vrednost populacijskega parametra.
Zgornja izjava je najpogostejša napaka glede intervala zaupanja. Po izračunu statističnega razpona lahko vsebuje samo populacijski parameter ali ne.
Vendar se intervali med vzorci lahko razlikujejo, medtem ko je dejanski populacijski parameter enak, ne glede na vzorec.
Zato se lahko izjava zaupanja v intervalih zaupanja poda samo v primeru, ko se intervali zaupanja ponovno izračunajo za število vzorcev.
Koraki za izračun intervala zaupanja
Razpon se izračuna z naslednjimi koraki:
- Zberite vzorčne podatke: n ;
- Izračunajte povprečno vrednost vzorca x̅;
- Določite ali je standardni odklon prebivalstva ( σ ) znan ali neznan;
- Če je standardna deviacija populacije znana, se lahko za ustrezno stopnjo zaupanja uporabi z-točka;
- Če standardni odklon prebivalstva ni znan, lahko uporabimo statistiko t za ustrezno stopnjo zaupanja;
- Tako najdemo spodnjo in zgornjo mejo intervala zaupanja z uporabo naslednjih formul:
a) Standardni odklon znane populacije :
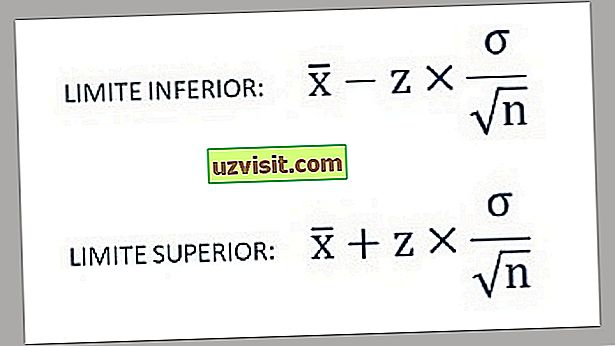
Formula za izračun standardnega odklona znane populacije.
b) Standardni odklon neznane populacije :

Formula za izračun standardnega odklona neznane populacije.
Praktični primer intervala zaupanja
Klinična študija je ovrednotila povezavo med prisotnostjo astme in tveganjem za razvoj obstruktivne apneje med spanjem pri odraslih.
Nekateri odrasli so bili naključno izbrani s seznama državnih uradnikov, ki naj bi jih spremljali štiri leta.
Udeleženci z astmo so v primerjavi s tistimi brez njih imeli večje tveganje za razvoj apneje v štirih letih.
Pri izvajanju kliničnih raziskav, kot je ta primer, se običajno zaposli podskupina interesne populacije, da bi povečali učinkovitost študija (manj stroškov in manj časa).
To podskupino posameznikov, populacijo, ki jo proučujemo, sestavljajo tisti, ki izpolnjujejo merila vključevanja in se strinjajo, da sodelujejo v študiji, kot je prikazano na spodnji sliki.

Nato se študija zaključi in izračuna se velikost učinka (na primer povprečna razlika ali relativno tveganje ), da se odgovori na raziskovalno vprašanje.
Ta proces, imenovan sklep, vključuje uporabo podatkov, zbranih iz študijske populacije, za oceno velikosti dejanskega učinka na populacijo, ki jo zanima, to je populacije izvora.
V danem primeru so raziskovalci zaposlili naključni vzorec državnih uslužbencev (izvorna populacija), ki so bili upravičeni in so se strinjali, da bodo sodelovali v študiji (študijska populacija) in poročali, da astma poveča tveganje za razvoj apneje v populaciji, ki je bila študija.
Da bi upoštevali napako vzorčenja zaradi zaposlovanja samo podskupine interesne populacije, so izračunali tudi 95-odstotni interval zaupanja (okoli ocene) od 1, 06 do 1, 82, kar kaže na verjetnost 95 %, da bi bilo dejansko relativno tveganje pri izvorni populaciji med 1, 06 in 1, 82 .
Interval zaupanja za povprečje
Če imamo podatke o standardni deviaciji populacije, lahko izračunamo interval zaupanja za povprečje ali povprečje te populacije.
Če je statistična značilnost, ki jo merimo (npr. Dohodek, IQ, cena, višina, količina ali teža) številčna, se v večini primerov ocenjuje, da je povprečna vrednost za populacijo najdena.
Zato poskušamo najti populacijsko sredino ( μ ) z uporabo vzorčne sredine ( x̅ ), z mejo napake. Rezultat tega izračuna se imenuje interval zaupanja za srednjo populacijo .
Če je standardna deviacija prebivalstva znana, je formula za interval zaupanja (CI) za populacijsko sredino:

Kje:
- x̅ pomeni sredino vzorca;
- σ je standardna deviacija prebivalstva;
- n je velikost vzorca;
- Represents * predstavlja ustrezno vrednost standardne normalne porazdelitve za želeno raven zaupanja.
V nadaljevanju so navedene vrednosti za različne stopnje zaupanja () * ):
| Raven zaupanja | Vrednost Z * - |
|---|---|
| 80% | 1.28 |
| 90% | 1.645 (običajno) |
| 95% | 1, 96 |
| 98% | 2.33 |
| 99% | 2.58 |
Zgornja tabela prikazuje vrednosti z * za določene stopnje zaupanja. Upoštevajte, da so te vrednosti dobljene iz standardne normalne porazdelitve (Z-).
Območje med vsako vrednostjo z * in negativ te vrednosti je (približen) odstotek zaupanja. Na primer, območje med z * = 1, 28 in z = -1, 28 je približno 0, 80. Zato je mogoče to tabelo razširiti tudi na druge odstotke zaupanja. Tabela prikazuje samo najpogosteje uporabljene odstotke zaupanja.
Glej tudi pomen hipoteze.


